AI Summary
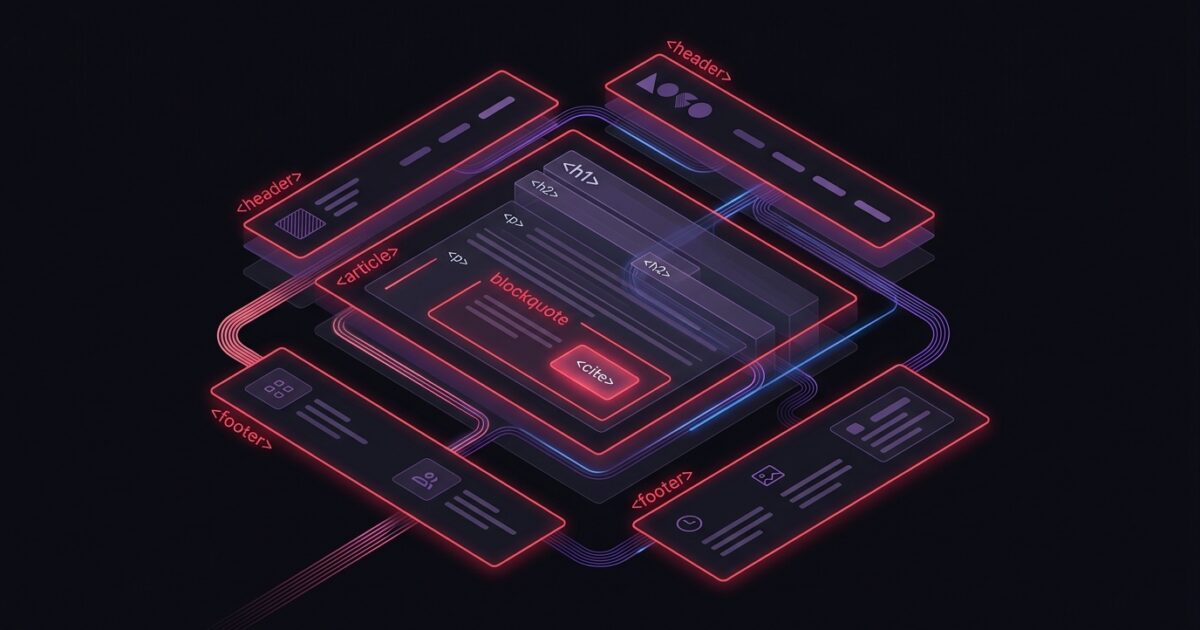
Semantic HTML5 tags are the primary structural signal that AI extraction pipelines use to identify article body versus page chrome, and most CMS templates ship with structural patterns that degrade extraction confidence without anyone noticing. This guide covers the 12 tags that matter most for AI parsers, how blockquote and cite improve source attribution, the article/section/div hierarchy AI engines actually read, the header and footer signals that strengthen E-E-A-T, and a six-step audit you can run on your top 20 URLs.
Why AI models parse semantic HTML differently than Googlebot

Googlebot has had two decades to forgive messy markup. It recovers from missing closing tags, infers structure from CSS classes, and renders JavaScript as part of its indexing process. AI extraction pipelines do none of that.
As Barry Adams documented in SEO for Google News, LLMs do not render JavaScript when they process webpages. Google is the exception because it has devoted substantial resources to rendering as part of indexing, and Gemini is the only LLM built on Google’s rendered index. For every other AI engine, ChatGPT and Perplexity included, the raw unrendered HTML is all they see. Semantic tags are the only structural signal available to them.
Adams frames the practical consequence directly: “It’s much simpler for ChatGPT to parse a few dozen semantic HTML tags rather than several hundred (or even thousand) nested div tags to find a webpage’s main content.” The structural tags tell the parser where the article starts and ends without requiring it to guess from font sizes, CSS classes, or layout heuristics. Google’s own documentation on image SEO best practices explicitly recommends using standard HTML image elements to help crawlers find and process content.
In our client work, we have run before-and-after audits on three sites where the only change was migrating template wrappers from div to article, section, header, and footer. Citation share in ChatGPT and Perplexity climbed within 60 to 90 days on every site. The fix was template-level, one change benefiting every page.
The 12 HTML5 tags that signal content structure to AI
Twelve elements do most of the structural work for AI parsers. Audit your templates against this list before doing anything else. Adams’ analysis in SEO for Google News identifies these as the structural semantic tags that help search engines and AI parsers understand the purpose and value of each section of HTML.
- article - Wraps the primary content unit. One per page for blog posts and guides.
- section - Thematic grouping inside an article. Use one per H2. One article per page, one section per H2.
- header - Site or article header. Inside an article it should hold the title, byline, and publish date.
- footer - Site or article footer. Use for author bio, citation list, and last-updated stamp.
- nav - Site or in-article navigation. Tells parsers what to ignore for body extraction.
- aside - Tangentially related content. Lower extraction priority, which is correct for chrome and sidebars.
- main - The single primary content region per page. Some parsers use this as the root for chunking.
- figure and figcaption - Image plus caption. Captions get pulled into AI summaries when present. Google’s image SEO guidance explicitly recommends the standard
imgelement insidefigureso crawlers can find and process images. - cite - Names a referenced source. Signals a verifiable attribution claim to the parser.
- blockquote with
citeattribute - Marks quoted material with attribution. Discussed in detail below. - time with
datetime- Machine-readable publish or update date. Critical for recency signals. - address - Author or organisation contact information inside a header or footer.
As Adams puts it: “Rather than cram your code full of div tags to make something happen, first see if there’s a proper HTML element that does the trick.” For AI parsers without JavaScript rendering, that proper element is the only structural signal available.
Using cite and blockquote to strengthen source attribution
Source attribution is an underrated lever in AI optimization. When you quote a study or third-party fact, wrapping the quote in a blockquote with a cite attribute pointing to the source URL, plus a cite child element naming the publication, gives AI parsers two layers of structured evidence. They can ingest the quote as a verifiable claim, attribute it correctly, and trace the citation back to the original without inferring intent from prose alone.
If and when the ‘agentic web’ comes to life (I’m skeptical), semantic HTML is likely a crucial aspect of success.
Barry Adams, SEO for Google News
The pattern we ship with every client engagement: every quoted block uses <blockquote cite="https://source-url"> wrapping the quote text in a paragraph, followed by a <cite>Source name</cite> child. The cite element names the work being cited, not the author. Most CMS rich-text editors get this wrong by default and output the author name in the cite element rather than the publication title. A small template adjustment fixes it across all content at once.
Our May 2026 study of 153,425 citations found that cited sentences have a mean length of 9.27 words and a median of 10 words, with none exceeding 18 words. Quoted blocks that are concise, declarative, and wrapped in proper blockquote markup match that citation profile exactly. Long block quotes wrapped in unsemantic div containers do not.
Article vs. section vs. div: what AI actually reads
This is the most common semantic confusion we see in client audits. article wraps a self-contained content unit. section wraps a thematic part of that article, typically one per H2. div is a generic container with no semantic meaning: use it only for layout purposes that have no structural intent.
AI parsers prioritize content inside article elements over content inside generic div wrappers. Inside the article, sections give the parser a chunking hint that maps directly to your H2 outline. Each H2-bounded section becomes an addressable chunk for retrieval, which is exactly the granularity that AI Overviews and Perplexity quote at. This connects directly to how content chunking for RAG works at the retrieval layer.
Check your own pages: confirm one article wrapping the primary content, one section per H2, and zero structural divs between them. Most WordPress themes break this with extra layout divs. Fix at the template level.
Header and footer elements for author E-E-A-T signals
E-E-A-T is the signal map every major AI engine uses to weight which sources are safe to cite. The header and footer elements inside an article are where you tell parsers who wrote the content and when.
Inside the article header: the title in an h1, a byline element naming the author, and a time element with datetime attribute marking publish and last-updated dates. Inside the article footer: an extended author bio with a link to the author profile page, an address element if the content is location-specific, and the citation list for sources referenced in the body.
- Author names wrapped in
<span itemprop="author">with corresponding Person schema for explicit entity attribution. - Publish dates use
<time datetime="2026-04-12">April 12, 2026</time>so the parser gets a machine-readable timestamp without guessing. - Last-updated dates use a separate
timeelement with a clear label so the parser does not conflate publish and update dates. - Author bios in the footer should include credentials and links to original research or external profiles. Our March 2026 study found that authorship signals correlate with citation rates on E-E-A-T-sensitive verticals.
- Citation lists in the footer use
<ol>with each item containing aciteelement naming the source. This is the HTML spec’s intended use of theciteelement at the page level.
Semantic HTML and structured data: complementary, not competing
A common question in our GEO audits: if you have JSON-LD schema markup on every page, do semantic tags still matter? Yes, and they serve different purposes.
Adams is direct: “Structured data won’t tell a machine which button adds a product to a cart, what subheading precedes a critical paragraph of text, and which links the reader should click on for more information.” Semantic HTML provides in-document structural context JSON-LD cannot replicate. Used together they are an unbeatable combination.
| Signal type | What it communicates | Where it lives |
|---|---|---|
| Semantic HTML (article, section, header) | Document structure and content hierarchy | In-document tag tree |
| JSON-LD schema | Entity type, author, dates, ratings | head or body script block |
| blockquote + cite | Quoted claim with source attribution | In-document inline |
| time + datetime | Machine-readable publish/update date | In-document inline |
The decision framework for JSON-LD vs. Microdata for AI search covers the schema layer in detail. Semantic HTML is the prerequisite layer: get the tag tree right first, then add schema on top.
Semantic HTML audit: six steps for AI readability
Run this six-step audit on your top 20 URLs once per quarter. It takes about three hours total and surfaces the structural issues that quietly suppress citations.
- HTML validator pass. Use the W3C validator (validator.w3.org) to catch missing closing tags and nesting errors. AI parsers tolerate less malformed HTML than browsers do.
- Tag tree check. Use
document.body.outerHTMLin browser DevTools or an outliner extension to see your actual semantic tree without CSS distractions. Confirm: onearticle, onesectionper H2, no structural divs between them. - Article-section count. A page should have exactly one
articlewrapping the primary content. Multiplearticleelements on a single post page signal a theme misconfiguration. - Citation markup check. Spot-check five quoted blocks. Each should use
blockquotewith aciteattribute and acitechild naming the source. This aligns with how our citation studies show AI engines process attributed claims. - Time element check. Confirm publish and updated dates use
timeelements withdatetimeattributes in ISO 8601 format. Missing machine-readable dates suppress recency signals in AI citation engines. - AI extraction test. Paste the URL into ChatGPT, Claude, and Perplexity with the prompt “Summarize the main claims in this article and name the author.” If any model misses the author or hallucinates the date, your header markup is failing.
One pattern that derails this audit: teams treat semantic HTML as content work rather than template work. The fix is almost always at the theme layer. Update the post template once and every page benefits. For WordPress specifically, the Web Components and Shadow DOM parsing guide covers cases where component-based themes introduce additional structural complexity that breaks the article-section hierarchy.
Semantic HTML is one layer in the full AI extraction stack. The image alt text guide, internal linking for AI search, and FAQPage vs HowTo schema decision cover the adjacent layers. Use our open-source GEO/AEO Tracker to validate semantic changes against actual citation outcomes.