AI Summary
Shadow DOM encapsulates component content away from the main DOM tree, and most AI crawlers cannot see inside it. Google Search Central confirms that Googlebot flattens Shadow DOM and Light DOM when rendering pages, but a December 2024 Vercel and MERJ analysis found that GPTBot, ClaudeBot, PerplexityBot, Meta-ExternalAgent, and Bytespider do not execute JavaScript at all. Without JavaScript execution, shadow root content is simply absent from what those bots read. This guide covers exactly how Shadow DOM affects AI crawler extraction, the verified behavior of each major bot, the light DOM architecture pattern that recovers visibility, how to handle schema inside web components, and a migration plan when critical content is currently locked inside shadow roots.
How Shadow DOM Encapsulation Works and Why It Matters for AI
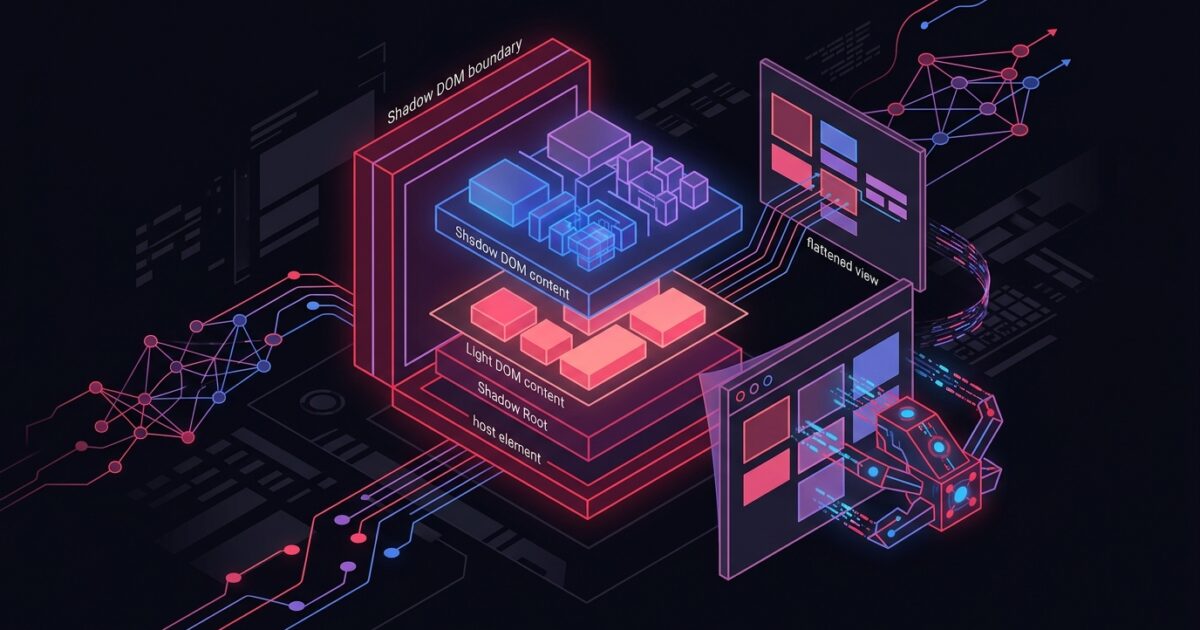
Shadow DOM is one of three Web Components standards alongside HTML Templates and Custom Elements. It lets a custom element attach a private DOM subtree, called a shadow root, that is isolated from the outer document. Styles cannot leak in or out. Scripts from the parent document cannot reach inside. The encapsulation is designed for component reuse and CSS isolation.
The isolation that makes Shadow DOM useful for component engineering also makes it invisible to crawlers that do not execute JavaScript. When an AI bot fetches a page without running its scripts, the custom element appears as an empty tag in the HTML. Any content rendered inside the shadow root by a JavaScript framework is absent from the raw document the bot reads. Product descriptions, author bios, FAQ blocks, and schema markup inside shadow roots are all equally invisible to those bots.
Declarative Shadow DOM (DSD) is a partial exception. Per web.dev’s documentation on Declarative Shadow DOM, DSD uses a template element with a shadowrootmode attribute that the HTML parser processes immediately, without JavaScript execution. DSD became Baseline Newly Available in August 2024, supported in Chrome 111, Edge 111, Firefox 123, and Safari 16.4. When shadow roots are created declaratively in server-rendered HTML, the shadow content is present in the initial HTML response and therefore visible to bots that do not execute JavaScript. This is the SSR-first path for web components and the correct architecture for AI-visible content.
Verified Bot Behavior: Who Sees Shadow DOM and Who Does Not
Google Search Central’s JavaScript SEO documentation states directly: “When Google renders a page, it flattens the shadow DOM and light DOM content.” The same page confirms that Googlebot sees content in shadow roots because it runs a full Chromium rendering engine.
The December 2024 Vercel and MERJ research analyzed nearly one billion AI crawler requests and found a clear split. Googlebot (4.5 billion monthly fetches) and AppleBot both execute JavaScript and flatten shadow roots. Google’s Gemini crawler uses Googlebot’s infrastructure, giving it the same rendering capability. Every other major AI crawler, including GPTBot (569M monthly fetches), ClaudeBot (370M monthly fetches), PerplexityBot (24.4M monthly fetches), Meta-ExternalAgent, and Bytespider, does not execute JavaScript. These bots fetch JavaScript files as static text but cannot render what those files produce.
| Bot | JavaScript Execution | Shadow DOM Visible | Monthly Fetches (Vercel) |
|---|---|---|---|
| Googlebot | Full (Chromium) | Yes | 4.5 billion |
| Google-Extended / Gemini | Full (via Googlebot infra) | Yes | Included above |
| AppleBot | Full (browser-based) | Yes | 314 million |
| GPTBot | None | No (light DOM only) | 569 million |
| ClaudeBot | None | No (light DOM only) | 370 million |
| PerplexityBot | None | No (light DOM only) | 24.4 million |
| Meta-ExternalAgent | None | No | Not reported |
The asymmetry is critical. Building for Googlebot only is the legacy game. Building for the full AI crawler ecosystem in 2026 means assuming that GPTBot and ClaudeBot, which together account for nearly one billion monthly fetches, cannot see shadow root content.

Light DOM vs. Shadow DOM: The AI Visibility Architecture Decision
The Web Components specification supports both light DOM and shadow DOM rendering. The architectural choice for any component that wraps citable content determines AI extraction across the full bot set.
- Light DOM rendering. The custom element’s content lives in the regular document tree, visible to every crawler regardless of JavaScript execution. CSS encapsulation is lost; styles from the parent document can reach in. This is the correct choice for any content that should be cited.
- Shadow DOM rendering. Content lives in a private shadow tree. Invisible to AI bots that do not execute JavaScript. Correct for structural templating, layout, and style isolation where citation is not needed.
- Slot-based composition. The custom element renders its structure in the shadow root but exposes a slot element. Content passed from the parent document into the slot lives in the light DOM and is visible to all crawlers. The shadow root provides encapsulation; the slot surface exposes the content.
- Declarative Shadow DOM with SSR. Shadow content is serialized into the server-rendered HTML using the shadowrootmode template attribute. The HTML parser attaches the shadow root without JavaScript execution, making the content present in the raw document that bots read.
The practical rule: citable content (headings, body text, author information, FAQ answers, product descriptions) belongs in the light DOM. Shadow DOM handles templates, style scoping, and structural layout that does not need to be cited. Slots bridge the two: pass light DOM content into shadow templates. The pattern lets a team keep the component model while recovering AI visibility for the content that matters.
The default behavior of common web component libraries (Lit, Stencil) is to render content into the shadow root. That default is wrong for any component wrapping citable content. Overriding it requires adding slot markup to the shadow template and passing content via slots at the usage site. The change is small and recovers full AI bot coverage for the slotted content.
Schema Markup Inside Web Components: Where It Must Go
Structured data inside web components faces the same visibility problem as content. JSON-LD added inside a shadow root is invisible to AI bots that do not execute JavaScript. JSON-LD added to the light DOM, even inside a custom element wrapper, is visible to every crawler.
The Google Search Central documentation on fixing JavaScript SEO problems states: “WRS flattens the light DOM and shadow DOM. If the web components you use aren’t using
- Render JSON-LD in the document head for page-level schema (Organization, WebSite, BreadcrumbList, Article). This is always in the light DOM and always visible.
- Render component-level JSON-LD in the light DOM body as a script tag adjacent to the custom element, not inside its shadow template.
- Avoid injecting JSON-LD via JavaScript after load. Even Googlebot picks up client-injected schema in many cases. GPTBot and ClaudeBot do not.
- Validate the raw HTML response contains the JSON-LD script tag before assuming structured data is shipping correctly. Use Google’s Rich Results Test or schema.org validator against the raw URL.
We run FAQ schema and Article schema audits as part of our standard GEO audit process. Schema inside shadow roots is one of the most common silent failures we find on component-heavy sites, particularly those built with design system frameworks that default to shadow DOM encapsulation.
Testing Shadow DOM Content Visibility
AI crawler visibility is testable before a deployment ships. A five-step battery covers the main failure modes and takes minutes per page type.
- Fetch raw HTML with curl or a plain HTTP GET. If your critical content (product description, FAQ answers, author bio) does not appear in the response body, no non-JS crawler sees it.
- Repeat with a GPTBot user agent string. The content and response should be identical. Any difference reveals bot-specific handling worth reviewing.
- Inspect with browser DevTools. Enable “Show user agent shadow DOM” in Settings. Content inside a closed shadow root that does not appear in the Elements panel as light DOM is suspect.
- Validate schema in the raw response. Run Google’s Rich Results Test against the page URL and verify JSON-LD appears. If it does not, the schema is inside a shadow root or injected client-side.
- Run direct prompt tests. Ask ChatGPT or Perplexity a question that specifically requires information from inside a shadow-rendered component. Inability to answer indicates extraction failure.
The AI crawler log file analysis approach is also useful here. Server logs show which pages AI bots fetched and whether they hit caching or errors. Pairing log data with citation tracking using our open-source GEO/AEO Tracker connects rendering behavior directly to citation outcomes.
Migration Plan: Moving Shadow Content to Light DOM
Shadow DOM migration does not require a full component library rewrite. A staged approach prioritizing the highest-value content recovers AI visibility within a single sprint.
- Audit and prioritize. Identify every component that wraps citable content: product descriptions, author bios, FAQ blocks, review snippets, and any container holding JSON-LD. Rank by traffic value and citation opportunity.
- Convert to slot-based content. Refactor each high-priority component so the shadow root provides the structural template and all citable content is passed via slot from the light DOM. The user-facing render is unchanged; AI bots now see the content in the raw HTML.
- Move JSON-LD out of shadow roots. Render every schema script tag in the document head or as a light DOM sibling to the custom element. Validate that schema parsers see the markup in the raw HTML response.
- Evaluate DSD for new components. For any new component built with SSR, use Declarative Shadow DOM. The shadowrootmode attribute keeps encapsulation while embedding shadow content in the server-rendered HTML that non-JS bots can read.
- Verify with the five-step test above and monitor citation rates using the AI Mode citation data and bot logs for 60 days post-deployment.
Migration timeline: phase 1 audit takes one day for a typical product site. Slot refactors and schema moves take one to two sprints depending on component count. Citation lift typically appears in the 30 to 60 day window after migration ships, as AI bots recrawl and re-evaluate the now-visible content. Our May 2026 study of 153,425 AI citations found that 76.95% of cited URLs are not in the organic top-10, confirming that AI citation is a distinct signal from organic rank. Technical visibility changes affect it directly.
For sites already on a headless stack with the rendering issues from the companion post on headless CMS AI search rendering, Shadow DOM migration is the component-level complement to the page-level SSR fix. Both layers need to be correct for full AI citation coverage. Our GEO optimization service covers both as part of a technical visibility engagement, with verification through page speed, schema, and live citation tracking.